Microsoft's Deep Learning framework "CNTK" is now compatible with Python, making it much easier to use
Do you know CNTK? For those who have already used some kind of Deep Learning framework, I think most of them say, "I know that MS is out there ...".
In fact, when I ask people around me, it seems that the learning cost is high for those who have seen articles written in DSL before the version is released. It seems that there are quite a lot of people who think that, in the first place, there are few Japanese documents about CNTK and they do not understand what kind of features they have.
Therefore, in this article, I would like to introduce CNTK, which has become easier to use with Python support, by sprinkling keywords such as its features and differences from other frameworks.
"Open-source, Cross-platform Toolkit"
Open development environment
It is open source and is under development on on GitHub.
Cross-platform development environment
Available on Linux and Windows. Docker for Linux (https://hub.docker.com/r/microsoft/cntk/) is also available.
Diverse interfaces
The following are currently supported:
- C++
- Brainscript
- Python (NEW!)
It went up to Version 2.0 in October 2016 and finally supports Python! (Tears) I think many engineers who use machine learning are Python users, so C ++ can be used with Brainscript anyway! Even if it is said, about 132 out of 100 people should be "Burein Sukuriputo ... ??". However, I think that the learning cost has dropped at once thanks to Python's support.
"Scalability"
I think the most attractive thing about CNTK is its scalability.
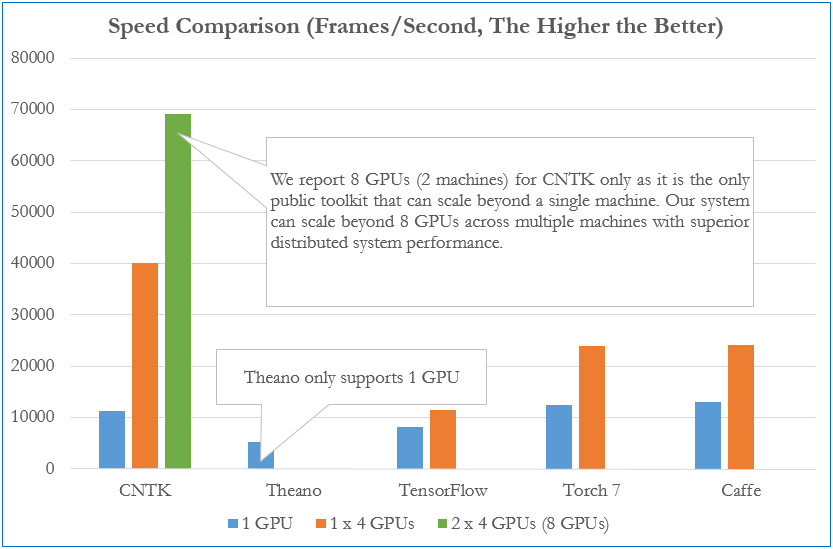
The figure above is a comparison of learning speeds by each framework (*). We are comparing how many frames can be processed per second by a fully connected 4-layer neural network. With one GPU, the speed is almost the same for each framework, but with multiple machines / GPUs, you can see that CNTK is overwhelmingly higher than the others.
- Comparison as of December 2015
 "Benchmarking State-of-the-Art Deep Learning Software Tools"
"Benchmarking State-of-the-Art Deep Learning Software Tools"
In addition, this is a benchmark for fully connected, AlexNet, ResNet, and LSTM (*). You can see that CNTK has the fastest performance in full join and LSTM. By the way, AlexNet is the fastest with Caffe, and ResNet is the fastest with Torch. The benchmark also shows that CNTK is a pioneer in the Deep Learning framework for all models and outperforms the most well-known TensorFlow. (This was pretty surprising ...)
- Comparison as of August 2016
"Efficient network authoring" At CNTK, the following ideas have been devised to create neural networks as efficiently and easily as possible.
- ** Composability that allows you to build any neural network by combining simple components **
- ** Handle neural networks as function objects **
For example, suppose a feedforward neural network with two hidden layers is expressed by a mathematical formula as follows.

In CNTK, you can write in a form similar to a mathematical formula.
h1 = Sigmoid(W1 * x + b1)
h2 = Sigmoid(W2 * h1 + b2)
P = Softmax(Wout * h2 + bout)
ce = CrossEntropy(y, P, tag='criterion')
Since CNTK treats neural networks as function objects, it is a great match for describing neural networks (including deep neural networks) that are very large and complex "functions". And thanks to Python support, you can write the structure of neural networks more concisely.
For example, the following is a sample image of a convolutional neural network (CNN) network commonly used in image recognition systems.
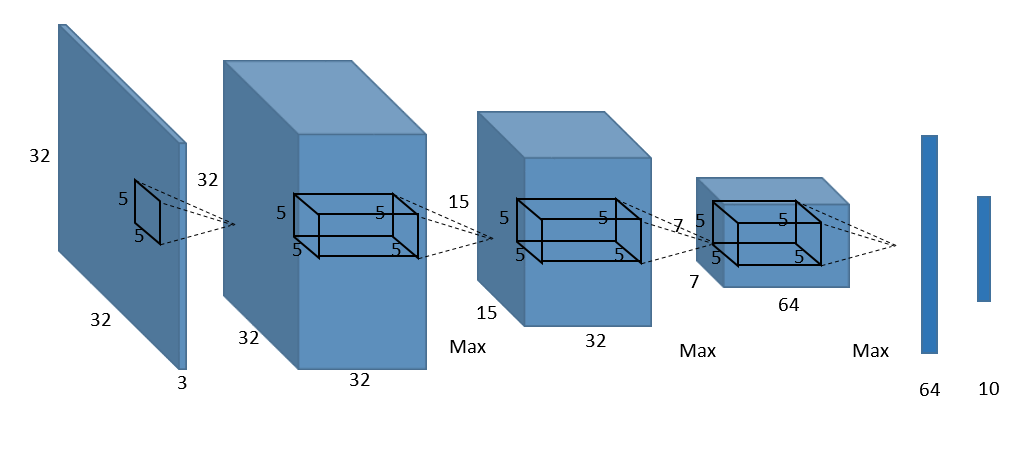
If you write the above network configuration straight in CNTK,
def create_basic_model(input, out_dims):
net = Convolution((5,5), 32, init=glorot_uniform(), activation=relu, pad=True)(input)
net = MaxPooling((3,3), strides=(2,2))(net)
net = Convolution((5,5), 32, init=glorot_uniform(), activation=relu, pad=True)(net)
net = MaxPooling((3,3), strides=(2,2))(net)
net = Convolution((5,5), 64, init=glorot_uniform(), activation=relu, pad=True)(net)
net = MaxPooling((3,3), strides=(2,2))(net)
net = Dense(64, init=glorot_uniform())(net)
net = Dense(out_dims, init=glorot_uniform(), activation=None)(net)
return net
You can write like this. However, this makes the code more redundant as the number of hidden layers increases. As I said earlier, CNTK is so focused on *** Composability *** that you can write it more simply and efficiently:
def create_model(input, out_dims):
with default_options(activation=relu):
model = Sequential([
For(range(3), lambda i: [
Convolution((5,5), [32,32,64][i], init=glorot_uniform(), pad=True),
MaxPooling((3,3), strides=(2,2))
]),
Dense(64, init=glorot_uniform()),
Dense(out_dims, init=glorot_uniform(), activation=None)
])
return model(input)
Use Sequential () to group each layer connected in a horizontal straight line, or if you want to use the same activation function or bias in multiple layers, use default_options () to implement the previous implementation. I am able to write the network more efficiently than the example.
Also, in CNTK, components such as CNN, ResNet, and RNN that are generally used are prepared as APIs (*), so it is very for ** "those who understand the neural network itself to some extent" **. It is a mechanism that makes it easy.
- I wrote a typical Python API for CNTK as the [Appendix] at the bottom, so please check what is available if you like.
"Efficient execution"
As mentioned above, one of the merits of using CNTK is high performance such as fast learning speed during training and efficient use of multiple GPUs, but these are unique to CNTK as follows. Because it has the function of.
- ** Convert to graph representation and learn **
- ** Proprietary parallel learning algorithm **
Learn by converting to graph representation
h1 = Sigmoid(W1 * x + b1)
h2 = Sigmoid(W2 * h1 + b2)
P = Softmax(Wout * h2 + bout)
ce = CrossEntropy(y, P, tag='criterion')
I will reprint the feedforward neural network with two hidden layers, which I took as an example earlier. Inside CNTK, the above script is first converted to a representation called Computation Graph, as shown below.

At this time, the nodes on the graph are functions, and the edges are the values. By converting to graph representation first in this way,
- ** Learning by automatic differentiation **
- ** Reduction of run-time memory and calculation costs by optimizing in advance **
Can be realized.
Equipped with a unique parallel learning algorithm
Block-Momentum SGD

From CNTK Version1.5 [Block-Momentum SGD](https://www.microsoft.com/en-us/research/publication/scalable-training-deep-learning-machines-incremental-block-training-intra-block- It implements a technology called parallel-optimization-blockwise-model-update-filtering /).
This significantly eliminates the cost of communication between GPUs and allows for faster speeds across multiple GPUs while maintaining accuracy.
In fact, in the task shown above, running on 64 GPU clusters performed more than 50 times better than on one.
1-bit SGD The bottleneck in distributed processing on the GPU is communication cost. However, CNTK is [1-bit SGD](https://www.microsoft.com/en-us/research/publication/1-bit-stochastic-gradient-descent-and-application-to-data-parallel-distributed -training-of-speech-dnns /), a technology that can eliminate communication costs by quantizing the gradient to 1 bit is implemented. As a result, the learning speed during training of the neural network can be improved so that the communication cost can be significantly reduced when performing parallel processing.
in conclusion
What did you think. I introduced the features of CNTK with a few points, but I think you may not have known it. What is CNTK this time? Since I focused on, I didn't touch on building the environment, but the support for python made building the environment much easier. Also, the Jupyter Notebook-based Tutorial is very rich, so if you are interested in CNTK after reading this article, please try CNTK in Tutorial! If you have any questions about environment construction or tutorial, Make style conversion with MS Deep Learning Framework CNTK-What if I let elementary school students draw Van Gogh? and Microsoft's Deep Learning Library "CNTK" Tutorial are written in detail. Please have a look there.
It would be great if the number of people who read this article and said, "Let's touch CNTK for a moment" will increase as much as possible! :)
[Appendix] Example of Python API for CNTK
- basic blocks:
- LTSM(), GRU(), RNNUnit()
- ForwardDeclaration(), Tensor[], SparseTensor[], Sequence[], SequenceOver[]
- layers:
- Dence(), Embedding()
- Convolution(), Convolution1D(), convolution3D(), Deconvolution()
- MaxPooling(), AveragePooling(), GlobalMaxPooling(), GlobalAveragePooling(), MaxUnpooling()
- BatchNormalization(), LayerNormalization()
- Dropout(), Activation()
- Label()
- composition:
- Sequential(), For()
- ResNetBlock(), SequentialClique()
- sequences:
- Delay(), PastValueWindows()
- Recurrence(), RecurrencFrom(), Fold(), UnfoldFrom()
- models:
- AttentionModel()
Recommended Posts